1강
모델링은 deterministic!
deterministic nature - obs에 근거해서 모델링을 해야 한다는 것이다. 어떤 경우 이런거 없이 모델링하는 경우, SE가 커지게 될 수 있는데 이를 over-parameterization이라고 한다. 이것은 바람직하지 못하기 때문에 가급적 사용하는 자료는 information (정보)가 있어야만 할 수 있다.
스케일링 파라메터란 무엇인가? 주는건 dosing amt. 단위는 주지 않는다. 따라서 단뒤를 맞추는 수단이 된다. 물통의 크기라고 볼수도 있다. dose와 농도의 크기 간에 관계를 맺어준다. 이것이 바로 volume of distribution이다! clearance는 각 사람이 약물을 제거하는 능력이 어떠한가이다. plasma volume을 시간으로 나눈 값이다. 설렁탕의 비유 - 시간이 갈수록 수가락에 올라오는 밥알의 개수는 줄게 된다. 청소율은 숟가락의 크기라고 볼 수 있다. 얼마나 숟가락질 하는지에 대해 생각해 볼수도 있다.
어떤 시간에서 어떤 농도인지 점들만 얻을 수 있다. 그런데 모델이란 structure이다. data와 structure를 주고 컴퓨터에서 ‘파라메터 estimate는 무엇인가?’ 를 계산하게 된다. 자료를 보고 어떤 구조인지 인간이 준다. plausible한 것을 찾아야 한다.
cp = dose / vd * exp(-cl/vd * t)
model diagnostics - 여러 구조 중에서 이것이 가장 좋은 구조라는 것을 결정해 줄 수 있다. 이것을 찾아가는 것이 modeling이라고 할 수 있다.
deductive knowledge가 된 것이다. learn & apply - 신약개발의 컨셉이라고 할 수 있다. 모델링은 지식을 사용해서 설명을 가장 잘하는 것을 찾아가는 것이다.
Justification!
기존 자료와 잘 들어맞고 prediction 했을 때
이것이 이뤄지지 않는다면 valid한 모델이라고 할 수 없다. 다른 사람과 소통할 때 consensus가 이루어져야 한다.
mixed effects model이란 무엇인가?
standard 2 stage 첫번째: individual을 구하고, 두번째: average, sd를 구하는 것이다.
mixed effects라고 하는 이유는 fixed와 random - population pharmacokinetics
기본적으로 파라메터가 어떤 분포를 따른다는 가정을 한다. 집단값을 정하고 개인의 값을 어떻게 정하게 될 것인가?
CL, V - 집단의 대표값을 갖고 있다. theta! PK parameter - log normal distribution을 한다는 것을 알고 있기 때문에 CL = theta1 * exp(eta1)로 표현을 하게 된다. V = theta2 * exp(eta2)
희소한 자료(sparse data)에서 MEM을 하는 것이 따라서 가능해진다.
설명되지 않는 것은 variability가 있고 intra-individual, inter-individual variability로 나뉘어진다.
PREDPP
ADVAN 1-4 built in ADVAN 6는 사용자 모델을 만들때 사용한다. 하나하나 그려 나가는 것이다.
$DES는 어떻게 연결되는지 알려줄 것이다.
Tips for choice of nonmem estimate - TCP
MLE에서 objective function value를 얻어낼 수 있다.
ofv는 작을 수록 좋다. 모델간의 비교는 어떻게 해야 하는가? 여러가지 방법이 있지만 nested라는 개념으로 생각할 수 있다.
nested 간에는 likelihood ratio test를 통해서 할 수 있다.
다른 하나는 residual error를 보고서 알 수 있다. FOCE에서는 CWRES를 이용해서 ploting을 해서 보게 된다. 그 모습이 고르게 보여야 하는데 model misspecification이라고 한다. 등분산 가정이 무너지는 경우에 대해 알고 있어야 한다. 농도 높은 부분을 설명 못하기 때문이다.
bootstrap, predictive check (VPC) 등을 많이 쓰고 있다. 왜 하냐? 그 모델을 가지고 시뮬레이션 하는데 bootstrap - 기존의 데이타를 조금 변경해서 넣어봤더니 맞더라. 기존에 갖고 있던 내 모델의 성능을 보는게 아니라 새로운 자료로 모델의 성능을 평가하는 것이다.
2강
흡수(absorption)란 무엇일까? 약물이 주입한 곳에서 측정 부위로 이동하는 것.
같은 time frame에 묶여 있다면 rate (k1, k2)는 amount (A1, A2)와 정확히 비례를 이루고 있다. 따라서 이 둘을 다 넣는 것은 over parameterization이 될 수 있다.
Heart failure등이 있으면 blood flow가 줄어서 first-pass metabolism에 영향을 받게 될 것이다. 대부분의 흡수는 위가 아니라 소장에서 일어난다. 표면적이 크기 때문이다. dissolution, GI 등을 고려할 때 단순한 1차 속도론을 따르지 않는다. 곡선이 복잡한 모습이라는 것이다. Lag time을 써서 사용하는 경우가 많다. 0에서부터 first order가 되기는 굉장히 힘들기 때문이다. 또한 1차 ka를 사용하는 것을 보완하고자 transit compartment model, erlang absorption model을 사용하는 방법이 있다. ka를 변화시키는 방법도 있는데 이것이 weibull type absroption 방법도 있다.
흡수 모델을 잘 맞춰야 다른 것도 맞출 수 있으므로 신경 써야 한다.
Dose proportionality가 없다는 것은 absorption의 saturation 때문이며, non linear elimination due to saturation과 혼동되면 안된다.
enterohepatic circulation이 있다면 반영을 해야 하고 생리학적 원인이 불분명할때 고려해야 할 것이다.
3강
zero-order absorption이 나타나는 상황은 다음과 같은 고려점이 있다.
- High permeability를 가진 약물에서 잘 나타난다.
- solubility가 좋으면 lag time이 없어지기도 한다. zero-order에 first-order를 적용하면 Cmax가 어그러지기 때문에 주의해야 한다.
lag time 마저도 estimation 할 수 있다.
IV model을 사용할 수 있다. D1 (duration), R1 (rate) 두개가 필요하다. ADVAN, TRANS를 정한다. ADVAN1 TRANS1 (microconstant k 같은 것을 가져온다.) TRANS2 (CL, V를 추정한다.)
CTL file을 쓴다.

ADVAN2 TRANS2를 쓰는 경우를 살펴본다. depot compartment가 있는 1st order absorption이 있는 것이다. 그런데 CWRES가 뒤집어진 U shape으로 나왔기 때문에 모델을 바꾸고자 한다. 그래서 zero-order로 바꿨고 더 나아가 lag time까지 추가했더니 더 좋아졌다.
F1*Dose, Ka # First order absorption
F2*Dose, D2, ALAG2 # F2 = 1-F1 # zero order absortion
First-order를 쓰려면 depot compartment가 필요한 것이다. 미분방정식을 살펴보면 다음과 같다.
dA/dt = -Ka * A1
Application을 몇개 살펴볼 수 있고 같은 약물, 다른 상황에서 weibull 혹은 first order 섞어서 할 수 있다.
COMP(DEPOT, DEFDOSE)
COMP(CENTRAL, DEFOBS)
4강 - 전상일 선생님 (Q-fitter) -
Sigmoid curve를 그리는 두가지 방법: numerical하게 풀거냐 아니면 compartment 추가하면서 할거냐?
https://www.ncbi.nlm.nih.gov/pubmed/22555854 https://link.springer.com/article/10.1007%2Fs10928-012-9247-3
Erlang-type absorption, transit compartment model에 대해서 배운다. 일련의 transit cmt가 있는데 얼랑에서는 트랜싯의 개수가 manually 정해져있고 정수개 일것이다. 트랜짓에는 트랜짓 개수를 추정을 한다. 얼랑에서는 ka가 없다. 그 대신 Ktr로 많이 쓴다. vs 트랜짓에서는 Ka를 추정하게 된다.
트랜짓에서는 감마분포를 따르게 된다. https://en.wikipedia.org/wiki/Gamma_distribution
감마 분포는 연속 확률분포로, 두 개의 매개변수를 받으며 양의 실수를 가질 수 있다. 감마 분포는 지수 분포나 푸아송 분포 등의 매개변수에 대한 켤레 사전 확률 분포이며, 이에 따라 베이즈 확률론에서 사전 확률 분포로 사용된다. 매개변수 {\displaystyle k} k가 정수인 경우 감마 분포는 얼랑 분포가 된다.
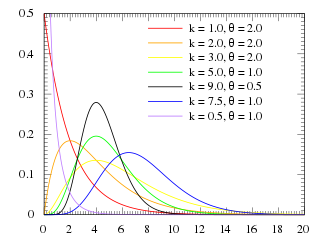

TCM에서는 그냥 식보다 지수함수로 바꿔서 하는게 더 빠르다. ADVAN5를 사용한 얼랑 모델을 시험해보자. (다만 ADVAN5는 느리다. ADVAN6를 쓰는게 더 나을 것이다.) Erlang과 TCM 두가지 모델의 차이점을 아는 것이 중요하다.
